Assertions
Introduction
Multitest’s assertion logic can be accessed via the result argument of the
testcase methods. Assertion methods can be called directly from the result object
(e.g. result.<assertion_method> or from its namespaces
result.<namespace>.<assertion_method>.
The content below contains testcase snippets, for complete examples please see please see here.
Execution Behavior
In Testplan, the testcase execution does NOT stop after a failing assertion. This is because in our experience, assertions are used to check for correctness of output values rather than determining which execution path was taken. Consequently, we find that it is more efficient to execute all assertions within a testcase, because it avoids the typical problem of fixing one assertion simply to find another one later on.
If some assertions rely on the result of previous ones and does not make sense
to be executed if the previous failed, the passed attribute of the returned
assertion entry can be used like this example:
@testcase def sample_testcase(self, env, result): item = get_item() entry = result.true(isinstance(item, dict), description='Check if dict') if entry.passed is True: result.contain('key', item.keys(), description='.keys() used')
If the test should be stopped on an assertion failure, an exception can be raised or use a return statement like this example:
@testcase def sample_testcase(self, env, result): entry = result.true(isinstance(5, float), description='Check if float') if entry.passed is False: raise RuntimeError('5 is not a float.') # Or result.log('5 is not a float. Aborting testcase.') return
Basic Assertions
Basic assertions can be used for common test cases, and accessible directly
from the result object.
result.true
Checks if the value is truthy.
@testcase def sample_testcase(self, env, result): result.true(isinstance(5, int), description='Truthiness check')Sample output:
$ test_plan.py --verbose ... Truthiness check - Pass ...
result.false
Checks if the value is falsy.
@testcase def sample_testcase(self, env, result): result.false(isinstance(5, str), description='Falsiness check')Sample output:
$ test_plan.py --verbose ... Falsiness check - Pass ...
result.fail
Creates an explicit failure, a common use case is to use it with conditions.
@testcase def sample_testcase(self, env, result): ... if unexpected_result: result.fail('Invalid outcome, result: {}'.format(unexpected_result))Sample output:
$ test_plan.py --verbose ... Invalid outcome, result: ... - Fail ...
result.equal / result.eq
Equality assertion, checks if reference is equal to the value.
@testcase def sample_testcase(self, env, result): result.equal('foo', 'foo', description='Equality example')Sample output:
$ test_plan.py --verbose ... Equality example - Pass foo == foo ...
result.not_equal / result.ne
Inequality assertion, checks if reference is not equal to the value.
@testcase def sample_testcase(self, env, result): result.equal('foo', 'bar', description='Inequality example')Sample output:
$ test_plan.py --verbose ... Inequality example - Pass foo != bar ...
result.less / result.lt
Comparison assertion, checks if reference is less than the value.
@testcase def sample_testcase(self, env, result): result.less(2, 12, description='Less comparison example')Sample output:
$ test_plan.py --verbose ... Less comparison example - Pass 2 < 12 ...
result.less_equal / result.le
Comparison assertion, checks if reference is less than or equal to the value.
@testcase def sample_testcase(self, env, result): result.less_equal(2, 12, description='Less equal comparison example')Sample output:
$ test_plan.py --verbose ... Less equal comparison example - Pass 2 <= 12 ...
result.greater / result.gt
Comparison assertion, checks if reference is greater than the value.
@testcase def sample_testcase(self, env, result): result.greater(10, 5, description='Greater comparison example')Sample output:
$ test_plan.py --verbose ... Greater comparison example - Pass 10 > 5 ...
result.greater_equal / result.ge
Comparison assertion, checks if reference is greater than or equal the value.
@testcase def sample_testcase(self, env, result): result.greater_equal(10, 5, description='Greater equal comparison example')Sample output:
$ test_plan.py --verbose ... Greater equal comparison example - Pass 10 >= 5 ...
result.isclose
Checks if first is close to second without requiring them to be exactly equal.
@testcase def sample_testcase(self, env, result): result.isclose(100, 101, rel_tol=0.01, abs_tol=0.0, description='Approximate equality example')Sample output:
$ test_plan.py --verbose ... Approximate equality example - Pass 100 ~= 101 (rel_tol: 0.01, abs_tol: 0.0) ...
result.contain
Membership assertion, checks if member is in the container.
@testcase def sample_testcase(self, env, result): result.contain('foo', ['foo', 'bar', 'baz'], description='List membership example')Sample output:
$ test_plan.py --verbose ... List membership example - Pass 'foo' in ['foo', 'bar', 'baz'] ...
result.not_contain
Membership assertion, checks if member is not in the container.
@testcase def sample_testcase(self, env, result): result.not_contain('foo', {'bar': 1, 'baz': 2}, description='Dict membership example')Sample output:
$ test_plan.py --verbose ... Dict membership example - Pass 'foo' not in {'bar': 1, 'baz': 2} ...
result.equal_slices
Equality assertion on iterable slices, checks if slices of reference is equal to slices of the value.
@testcase def sample_testcase(self, env, result): result.equal_slices( [1, 2, 3, 4, 5, 6, 7, 8], ['a', 'b', 3, 4, 'c', 'd', 7, 8], slices=[slice(2, 4), slice(6, 8)], description='Comparison of slices' )Sample output:
$ test_plan.py --verbose ... Comparison of slices - Pass slice(2, 4, None) Actual: [3, 4] Expected: [3, 4] slice(6, 8, None) Actual: [7, 8] Expected: [7, 8] ...
result.equal_exclude_slices
Equality assertion on iterables, checks if the items of reference and value which are outside the given slices match.
result.equal_exclude_slices( [1, 2, 3, 4, 5], ['a', 'b', 3, 4, 5], slices=[slice(0, 2)], description='Comparison of slices (exclusion)' )Sample output:
$ test_plan.py --verbose ... Comparison of slices (exclusion) - Pass slice(0, 2, None) Actual: [3, 4, 5] Expected: [3, 4, 5] ...
result.raises
Should be used as a context manager, checks if the block of code raises any of the given error types.
Supports additional checks via pattern and func arguments.
@testcase def sample_testcase(self, env, result): with result.raises(KeyError): {'foo': 3}['bar'] # Exception message pattern check (`re.search` is used implicitly) with result.raises( ValueError, pattern='foobar', description='Exception raised with custom pattern.' ): raise ValueError('abc foobar xyz') # Custom function check (func should accept # exception object as a single arg) class MyException(Exception): def __init__(self, value): self.value = value def custom_func(exc): return exc.value % 2 == 0 with result.raises( MyException, func=custom_func, description='Exception raised with custom func.' ): raise MyException(4)Sample output:
$ test_plan.py --verbose ... Exception Raised - Pass <type 'exceptions.KeyError'> instance of KeyError Exception raised with custom pattern. - Pass <type 'exceptions.ValueError'> instance of ValueError Pattern: foobar Exception message: abc foobar xyz Exception raised with custom func. - Pass <class '__main__.MyException'> instance of MyException Function: <function custom_func at 0x7fe66809b140> ...
result.not_raises
Should be used as a context manager, checks if the block of code does not raise any of the given error types.
Supports additional checks via pattern and func arguments, meaning it can also check if a certain type
of exception has been raised without matching the given pattern or func.
@testcase def sample_testcase(self, env, result): class MyException(Exception): def __init__(self, value): self.value = value def custom_func(exc): return exc.value % 2 == 0 # `not_raises` passes when raised exception # type does match any of the declared exception classes # It is logically inverse of `result.raises`. with result.not_raises(TypeError): {'foo': 3}['bar'] # `not_raises` can also check if a certain exception has been raised # WITHOUT matching the given `pattern` or `func` # Exception type matches but pattern does not -> Pass with result.not_raises( ValueError, pattern='foobar', description='Exception not raised with custom pattern.' ): raise ValueError('abc') # Exception type matches but func does not -> Pass with result.not_raises( MyException, func=custom_func, description='Exception not raised with custom func.' ): raise MyException(5)Sample output:
$ test_plan.py --verbose ... Exception Not Raised - Pass <type 'exceptions.KeyError'> not instance of TypeError Exception not raised with custom pattern. - Pass <type 'exceptions.ValueError'> not instance of ValueError Pattern: foobar Exception message: abc Exception not raised with custom func. - Pass <class '__main__.MyException'> not instance of MyException Function: <function custom_func at 0x7fcddcb171b8> ...
result.diff
Line diff assertion. Checks if textual content first and second have difference with given options.
If difference found, generates a list of strings showing the delta.
@testcase def sample_testcase(self, env, result): first, second = '', '' with open('1.txt', 'r') as f1: first = f1.read() with open('2.txt', 'r') as f2: second = f2.read() result.diff( first, second, unified=3, description='Compare 1.txt and 2.txt in unified mode' ) result.diff( ['bacon\r\n', 'eggs\r\n', 'ham\r\n', 'guido\r\n'], ['python\n', 'eggy\n', 'h a m\n', 'monty\n', '\tguido\n'], ignore_whitespaces=True, description='Compare 2 lists of text with whitespaces ignored' )Sample output:
$ test_plan.py --verbose ... Compare 1.txt and 2.txt in unified mode - Pass a.text: aaa bbb ccc ddd eee [truncated]... b.text: aaa bbb ccc ddd eee [truncated]... a.text == b.text Compare 2 lists of text with whitespaces ignored - Fail File: /d/d1/shared/yitaor/ets.testplan/ets/testplan/testplan/run/test_script.py Line: 49 a.text: bacon eggs ham guido b.text: python eggy h a m monty guido Differences ( -w ): 1,2c1,2 < bacon < eggs --- > python > eggy 3a4 > monty ...
result.log
Add a log entry in the console output and the report to make the output more human readable.
@testcase def sample_testcase(self, env, result): result.log( 'Start driver "{}"'.format(env.db.cfg.name)) result.log( 'Database file "{}" of driver "{}" created at "{}"'.format( env.db.cfg.db_name, env.db.cfg.name, env.db.db_path), description='Details of database file')) data = {100: 'foo', 200: ['bar', 'baz']} result.log(data, description='Log of raw data')$ test_plan.py --verbose ... Start driver "db" Details of database file Database file "mydb" of driver "db" created at "path/to/mydb" Log of raw data {100: 'foo', 200: ['bar', 'baz']} ...
result.markdown
Add Markdown into the report. Useful for displaying blocks of formatted text, code, messages, images etc. Downloadable examples that use markdown assertion can be found here.
result.markdown(""" Testplan is a [Python](http://python.org) package that can start a local live environment, setup mocks, connections to services and run tests against these. """, description="Testplan" )
result.log_html
A shortcut of result.markdown but disable escape flag.
Downloadable examples that use html assertion can be found here.
result.html(""" <div style="font-size:80px;font-family:Arial;font-weight:bold;"> <i class="fa fa-check-square" style="color:green;padding-right:5px;"></i> Testplan </div> """, description="Testplan" )
Warning
Embedded HTML does not support <script> tags. HTML5 specifies script tags within innerHTML shall not execute.
result.log_code
Add source code into the report. Useful for displaying source code which generated from a code-generation tool. Downloadable examples that use codelog assertion can be found here.
result.html(""" import this """, language="python" )
result.skip
Skip a testcase with the given reason. Downloadable examples that use skip assertion can be found here.
result.skip(reason="skip me")
result.matplot
Displays a Matplotlib plot in the report. Downloadable examples that use matplot assertion and contain output sample images can be found here.
result.plotly
Note
Testplan should be installed with plotly extra in order to use
this assertion.
Displays a Plotly figure in the report. Downloadable examples that use plotly assertion can be found here.
Assertion Groups
While writing assertions, it’s possible to group them together for formatting purposes. Some exporters (e.g. JSON, PDF) may make use of these groups to display assertion data in a certain format.
Console output will omit assertion groups and render assertion in flat format.
@testcase def assertion_group_sample(self, env, result): result.equal(1, 1, description='Equality assertion outside the group') with result.group(description='Custom group description') as group: group.not_equal(2, 3, description='Assertion within a group') group.greater(5, 3) # Groups can have sub groups as well: with group.group(description='This is a sub group') as sub_group: sub_group.less(6, 3, description='Assertion within sub group') result.equal( 'foo', 'foo', description='Final assertion outside all groups')
Assertion Summaries
Testplan supports summarization of assertion data, which is quite useful if there are testcases that contain a large number of assertions. It is possible to enable summarization at testcase level (via testcase parameters) or block level (via assertion groups).
It is possible to control number of passing / failing assertions per category per assertion type
via num_passing and num_failing optional arguments.
@testcase(summarize=True) def testcase_summarization(self, env, result): # Result data will contain a subset of failing / passing assertions for i in range(5000): result.equal(i, i) result.equal(i, i + 1) @testcase def block_summarization(self, env, result): result.equal('foo', 'bar', 'Assertion outside summary context') with result.group( summarize=True, num_passing=1, num_failing=2, description='Block level summary description', ) as group: for i in range(5000): result.equal(i, i) result.less(i, i + 1)
Normally Testplan will group all assertions of the same type under DEFAULT category,
however this can be overridden by explicitly passing category argument while declaring assertions:
@testcase(summarize=True) def testcase_summarization(self, env, result): for i in range(5000): # Assertions will be summarized under DEFAULT - Equal result.equal(i, i) # Assertions will be summarized under Multiples - Equal result.equal(i * 2, i * 2, category='Multiples')
This schema highlights the structure of a summarised output
Testplan Summary | +---- Category: DEFAULT -> (default category is for assertions not specified by the category argument) | | | +---- Assertion Type -> (e.g result.Equal) | | ( Description: summarising passing or failing assertions) | | | | | +---- assertion statement 1 | | | ( ... assertion details) | | | | | +---- assertion statement 2 | | | ( ... assertion details) | +---- Category: Multiples -> (specified by category argument) | | | +---- Assertion Type -> (e.g result.Equal) | | Description: summarising passing or failing assertions) | | | | | +---- assertion statement 1 | | | ( ... assertion details) | | | | | +---- assertion statement 2 | | | ( ... assertion details) | | Testplan Summary | ...
num_passing and num_failing will define how many assertion statements will be displayed in the schema above
key_combs_limit is used for fix/dict summaries and limits the number of failed key combinations reported
(For example: when applying result.dict.match to many different dictionaries with different keys,
there will be many ‘key combinations’ as failures, so only the key combinations with the most differences
will be reported, limited by key_combs_limit)
For further examples on summarization, please see the a downloadable example.
Assertion Namespaces
The result argument of a testcase method contains namespaces for more specialized assertion operations.
These namespace objects have API similar to result object when it comes to
writing assertions (e.g. result.<namespace>.<assertion_method>)
Regex Assertions (result.regex)
Contains assertion methods for regular expression based checks.
result.regex.match
Checks if the given regexp (string pattern or compiled re object) matches (re.match) the value.
@testcase def sample_testcase(self, env, result): result.regex.match( regexp='foo', value='foobar', description='string pattern match') result.regex.match( regexp=re.compile('foo'), value='foobar', description='SRE match')Sample output:
$ test_plan.py --verbose ... string pattern match - Pass foobar SRE match - Pass foobar ...
result.regex.multiline_match
Checks if the given regexp matches (re.match) the value, uses (re.DOTALL and re.MULTILINE) flags implicitly.
@testcase def sample_testcase(self, env, result): result.regex.multiline_match( regexp='first line.*second', value=os.linesep.join([ 'first line', 'second line', 'third line' ]), description='Multiline match example' )Sample output:
$ test_plan.py --verbose ... Multiline match example - Pass first line second line third line ...
result.regex.not_match
Checks if the given regexp does not match the value.
@testcase def sample_testcase(self, env, result): result.regex.not_match('baz', 'foobar')Sample output:
$ test_plan.py --verbose ... Regex Match Not Exists - Pass Pattern: `baz`, String: `foobar` ...
result.regex.multiline_not_match
Checks if the given regexp does not match the value, uses (re.DOTALL and re.MULTILINE) flags implicitly.
@testcase def sample_testcase(self, env, result): result.regex.multiline_not_match( regexp='foobar', value=os.linesep.join([ 'first line', 'second line', 'third line' ]), description='Multiline not match example' )Sample output:
$ test_plan.py --verbose ... Multiline not match example - Pass Pattern: `foobar`, String: `first line second line third line ...
result.regex.search
Checks if re.search operation on the given text returns a match.
@testcase def sample_testcase(self, env, result): result.regex.search('bar', 'foobarbaz')Sample output:
$ test_plan.py --verbose ... Regex Search - Pass foobarbaz ...
result.regex.search_empty
Checks if re.search operation on the given text does not return a match.
@testcase def sample_testcase(self, env, result): result.regex.search_empty('aaa', 'foobarbaz')Sample output:
$ test_plan.py --verbose ... Passing search empty - Pass Pattern: `aaa`, String: `foobarbaz` ...
result.regex.findall
Checks if given regexp exists in the value via re.finditer
and optionally runs a condition callable against the number of matches.
from testplan.common.utils import comparison @testcase def sample_testcase(self, env, result): text = 'foo foo foo bar bar foo bar' result.regex.findall( regexp='foo', value=text, condition=lambda num_matches: 2 < num_matches < 5, description='Find all with lambda condition', ) # Equivalent assertion with more readable output result.regex.findall( regexp='foo', value=text, condition=comparison.Greater(2) & comparison.Less(5), description='Find all with readable condition' )Sample output:
$ test_plan.py --verbose ... Find all with lambda condition - Pass foo foo foo bar bar foo bar Condition: <function <lambda> at 0x7fa42e6cfcf8> Find all with readable condition - Pass foo foo foo bar bar foo bar Condition: (<value> > 2 and <value> < 5) ...
result.regex.matchline
Checks if the given regexp returns a match (re.match) for any of the lines in the value.
@testcase def sample_testcase(self, env, result): result.regex.matchline( regexp=re.compile(r'\w+ line$'), value=os.linesep.join([ 'first line', 'second aaa', 'third line' ]), )Sample output:
$ test_plan.py --verbose ... Regex Match Line - Pass first line second aaa third line ...
Table Assertions (result.table)
Contains assertion logic for comparing tables. A table may be represented as a list of dictionaries with uniform keys or a list of lists with the first item representing the column names and the rest corresponding to the rows.
result.table.match
Compares two tables, uses equality for each table cell for plain values and supports regex / custom comparators as well.
from testplan.common.utils import comparison @testcase def sample_testcase(self, env, result): # Table in list of lists format actual_table = [ ['name', 'age'], ['Bob', 32], ['Susan', 24], ['Rick', 67] ] # Compare table with itself, plain comparison for each cell result.table.match(actual_table, actual_table) # Another table with regexes & custom comparators expected_table = [ ['name', 'age'], [ re.compile(r'\w{3}'), comparison.Greater(30) & comparison.Less(40) ], ['Susan', 24], [comparison.In(['David', 'Helen', 'Rick']), 67] ] result.table.match( actual_table, expected_table, description='Table match with custom comparators' )Sample output:
$ test_plan.py --verbose ... Table Match - Pass +----------------+----------+ | name | age | +----------------+----------+ | Bob == Bob | 32 == 32 | | Susan == Susan | 24 == 24 | | Rick == Rick | 67 == 67 | +----------------+----------+ Table match with custom comparators - Pass +-----------------------------------------------+---------------------------------------+ | name | age | +-----------------------------------------------+---------------------------------------+ | Bob == REGEX('\w{3}') | 32 == (<value> > 30 and <value> < 40) | | Susan == Susan | 24 == 24 | | Rick == <value> in ['David', 'Helen', 'Rick'] | 67 == 67 | +-----------------------------------------------+---------------------------------------+ ...
result.table.diff
Find differences of two tables, uses equality for each table cell for plain values and supports regex / custom comparators as well.
from testplan.common.utils import comparison @testcase def sample_testcase(self, env, result): # Table in list of lists format actual_table = [ ['name', 'age'], ['Bob', 32], ['Susan', 24], ['Rick', 67] ] # Compare table with itself, plain comparison for each cell result.table.diff(actual_table, actual_table) # Another table with regexes & custom comparators expected_table = [ ['name', 'age'], [ re.compile(r'\w{3}'), comparison.Greater(35) & comparison.Less(40) ], ['Susan', 24], [comparison.In(['David', 'Helen']), 67] ] result.table.diff( actual_table, expected_table, description='Table diff with custom comparators' )Sample output:
$ test_plan.py --verbose ... Table Diff - Pass Table diff with custom comparators - Fail File: .../test_plan.py Line: 95 +-----+-----------------------------------+-------------------------------+ | row | name | age | +-----+-----------------------------------+-------------------------------+ | 0 | Bob == REGEX('\w{3}') | 32 != (VAL > 35 and VAL < 40) | | 2 | Rick != VAL in ['David', 'Helen'] | 67 == 67 | +-----+-----------------------------------+-------------------------------+ ...
result.table.log
Logs a table to console output and the report.
sample_table = [ ['symbol', 'amount'], ['AAPL', 12], ['GOOG', 21], ['FB', 32], ['AMZN', 5], ['MSFT', 42] ] result.table.log(sample_table, description='My table.')My table. +--------+--------+ | symbol | amount | +--------+--------+ | AAPL | 12 | | GOOG | 21 | | FB | 32 | | AMZN | 5 | | MSFT | 42 | +--------+--------+
You can also log a link in the table cell.
from testplan.common.serialization.fields import LogLink result.table.log( [ ["Description", "Data"], [ "External Link", LogLink(link="https://www.google.com", title="Google"), ], ] ) # Require plan.runnable.disable_reset_report_uid() in main function # to avoid generating uuid4 as the report uid so that we can use # the test name as the link in the report. result.table.log( [ ["Description", "Data"], [ "Internal Link", # Add an internal link LogLink(link="/multitest1", title="multitest1", inner=True), ], ] )
Or a custom format value.
import time from testplan.common.serialization.fields import FormattedValue current_timestamp = time.time() result.table.log( [ ["Description", "Data"], [ "Formatted Value - date", FormattedValue( display=time.strftime("%H:%M:%S", time.gmtime(current_timestamp)), value=current_timestamp, ), ], ] )
result.table.column_contain
Can be used for checking if all of the values of a table’s column contain values from a given list.
@testcase def sample_testcase(self, env, result): sample_table = [ ['symbol', 'amount'], ['AAPL', 12], ['GOOG', 21], ['FB', 32], ['AMZN', 5], ['MSFT', 42] ] result.table.column_contain( values=['AAPL', 'AMZN'], table=sample_table, column='symbol', )Sample output:
$ test_plan.py --verbose ... Column Contain - Fail File: ..../test_plan.py Line: 361 Values: AAPL, AMZN +--------+--------+ | symbol | Passed | +--------+--------+ | AAPL | Pass | | GOOG | Fail | | FB | Fail | | AMZN | Pass | | MSFT | Fail | +--------+--------+
Dict Assertions (result.dict)
Contains assertion methods that operate on dictionaries.
result.dict.check
Checks existence / absence of keys of a dictionary.
@testcase def sample_testcase(self, env, result): result.dict.check( dictionary={ 'foo': 1, 'bar': 2, 'baz': 3, }, has_keys=['foo', 'alpha'], absent_keys=['bar', 'beta'] )Sample output:
$ test_plan.py --verbose ... Dict Check - Fail File: .../test_plan.py Line: 440 Existence check: ['foo', 'alpha'] Missing keys: ['alpha'] Absence check: ['bar', 'beta'] Key should be absent: ['bar']
result.dict.match
Matches two (nested) dictionaries against each other.
expected dictionary can contain custom comparators as values.
from testplan.common.utils import comparison @testcase def sample_testcase(self, env, result): actual = { 'foo': 1, 'bar': 2, } expected = { 'foo': 1, 'bar': 5, 'extra-key': 10, } result.dict.match(actual, expected, description='Simple dict match') actual = { 'foo': { 'alpha': [1, 2, 3], 'beta': {'color': 'red'} } } expected = { 'foo': { 'alpha': [1, 2], 'beta': {'color': 'blue'} } } result.dict.match(actual, expected, description='Nested dict match') actual = { 'foo': [1, 2, 3], 'bar': {'color': 'blue'}, 'baz': 'hello world', } expected = { 'foo': [1, 2, lambda v: isinstance(v, int)], 'bar': { 'color': comparison.In(['blue', 'red', 'yellow']) }, 'baz': re.compile(r'\w+ world'), } result.dict.match( actual, expected, description='Dict match: Custom comparators')Sample output:
$ test_plan.py --verbose ... Simple dict match - Fail File: .../test_plan.py Line: 394 (Passed) Key(foo), 1 <int> == 1 <int> (Failed) Key(bar), 2 <int> != 5 <int> (Failed) Key(extra-key), ABSENT <None> != 10 <int> Nested dict match - Fail File: .../test_plan.py Line: 412 (Failed) Key(foo), (Failed) Key(alpha), (Passed) 1 <int> == 1 <int> (Passed) 2 <int> == 2 <int> (Failed) 3 <int> != None <None> (Failed) Key(beta), (Failed) Key(color), red <str> != blue <str> Dict match: Custom comparators - Pass (Passed) Key(baz), hello world <str> == \w+ world <REGEX> (Passed) Key(foo), (Passed) 1 <int> == 1 <int> (Passed) 2 <int> == 2 <int> (Passed) 3 <int> == <lambda> <func> (Passed) Key(bar), (Passed) Key(color), blue <str> == <value> in ['blue', 'red', 'yellow'] <func>
result.dict.log
Add a log entry of dictionary in the console output and the report to make the output more human readable.
@testcase def sample_testcase(self, env, result): dictionary = { 'abc': ['a', ['b', 'c'], {'d': 'e', 'f': 'g'}], 'xyz': (True, False, None), 'alpha': ['foobar', {'f': 'foo', 'b': 'bar'}], 'beta': 'hello world' } result.dict.log({}, description='Log an empty dictionary') result.dict.log(dictionary)Sample output:
$ test_plan.py --verbose ... Log an empty dictionary (empty) Dict Log Key(alpha), foobar <str> Key(b), bar <str> Key(f), foo <str> Key(xyz), True <bool> False <bool> None <None> Key(abc), a <str> b <str> c <str> Key(d), e <str> Key(f), g <str> Key(beta), hello world <str> ...
Fix Assertions (result.fix)
Contains assertion methods that operate on Fix messages.
result.fix.check
Checks existence / absence of tags in a Fix message.
@testcase def sample_testcase(self, env, result): # Fix msg can be represented as a dictionary fix_msg = { 36: 6, 22: 5, 55: 2, 38: 5, 555: [ .. more nested data here ... ] } result.fix.check( msg=fix_msg, has_tags=[26, 22, 11], absent_tags=[444, 555], )Sample output:
$ test_plan.py --verbose ... Fix Check - Fail File: .../test_plan.py Line: 525 Existence check: [26, 22, 11] Missing keys: [26, 11] Absence check: [444, 555] Key should be absent: [555]
result.fix.match
Similar to result.dict.match, matches 2 (nested) fix messages, expected message supports custom comparators as well.
@testcase def sample_testcase(self, env, result): fix_msg_1 = { 36: 6, 22: 5, 55: 2, 38: 5, 555: [ { 600: 'A', 601: 'A', 683: [ { 688: 'a', 689: 'a' }, { 688: 'b', 689: 'b' } ] }, { 600: 'B', 601: 'B', 683: [ { 688: 'c', 689: 'c' }, { 688: 'd', 689: 'd' } ] } ] } fix_msg_2 = { 36: 6, 22: 5, 55: 2, 38: comparison.GreaterEqual(4), 555: [ { 600: 'A', 601: 'B', 683: [ { 688: 'a', 689: re.compile(r'[a-z]') }, { 688: 'b', 689: 'b' } ] }, { 600: 'C', 601: 'B', 683: [ { 688: 'c', 689: comparison.In(('c', 'd')) }, { 688: 'd', 689: 'd' } ] } ] } result.fix.match(fix_msg_1, fix_msg_2)Sample output:
$ test_plan.py --verbose ... Fix Match - Fail File: .../test_plan.py Line: 527 (Failed) Key(555), (Failed) (Passed) Key(600), A <str> == A <str> (Failed) Key(601), A <str> != B <str> (Passed) Key(683), (Passed) (Passed) Key(688), a <str> == a <str> (Passed) Key(689), a <str> == [a-z] <REGEX> (Passed) (Passed) Key(688), b <str> == b <str> (Passed) Key(689), b <str> == b <str> (Failed) (Failed) Key(600), B <str> != C <str> (Passed) Key(601), B <str> == B <str> (Passed) Key(683), (Passed) (Passed) Key(688), c <str> == c <str> (Passed) Key(689), c <str> == <value> in ('c', 'd') <func> (Passed) (Passed) Key(688), d <str> == d <str> (Passed) Key(689), d <str> == d <str> (Passed) Key(36), 6 <int> == 6 <int> (Passed) Key(38), 5 <int> == <value> >= 4 <func> (Passed) Key(22), 5 <int> == 5 <int> (Passed) Key(55), 2 <int> == 2 <int>
result.fix.log
Add a log entry of fix message in the console output and the report to make the output more human readable.
from pyfixmsg.fixmessage import FixMessage, FixFragment from pyfixmsg.reference import FixSpec from pyfixmsg.codecs.stringfix import Codec spec_filename = '/ms/dist/fsf/PROJ/quickfix/1.14.3.1ms/common/gcc47_64/share/quickfix/FIX42.xml' spec = FixSpec(spec_filename) codec = Codec(spec=spec, fragment_class=FixFragment) def fixmsg(*args, **kwargs): returned = FixMessage(*args, **kwargs) returned.codec = codec return returned @testcase def sample_testcase(self, env, result): data = (b'8=FIX.4.2|9=196|35=X|49=A|56=B|34=12|52=20100318-03:21:11.364' b'|262=A|268=2|279=0|269=0|278=BID|55=EUR/USD|270=1.37215' b'|15=EUR|271=2500000|346=1|279=0|269=1|278=OFFER|55=EUR/USD' b'|270=1.37224|15=EUR|271=2503200|346=1|10=171|') message = fixmsg().load_fix(data, separator='|') result.fix.log(message, description='Log a fix message')Sample output:
$ test_plan.py --verbose ... Log a fix message Key(34), 12 <str> Key(35), X <str> Key(262), A <str> Key(8), FIX.4.2 <str> Key(9), 196 <str> Key(10), 171 <str> Key(268), Key(279), 0 <str> Key(269), 0 <str> Key(270), 1.37215 <str> Key(15), EUR <str> Key(278), BID <str> Key(55), EUR/USD <str> Key(346), 1 <str> Key(271), 2500000 <str> Key(279), 0 <str> Key(269), 1 <str> Key(270), 1.37224 <str> Key(15), EUR <str> Key(278), OFFER <str> Key(55), EUR/USD <str> Key(346), 1 <str> Key(271), 2503200 <str> Key(49), A <str> Key(52), 20100318-03:21:11.364 <str> Key(56), B <str> ...
XML Assertions (result.xml)
Contains assertion methods that operate on XML strings.
result.xml.check
Checks if given tags / paths exist in the XML string, supports namespace lookups and value/regex matching for tag values.
@testcase def sample_testcase(self, env, result): xml_1 = ''' <Root> <Test>Foo</Test> </Root> ''' result.xml.check( element=xml_1, xpath='/Root/Test', description='Simple XML check for existence of xpath.' ) xml_2 = ''' <Root> <Test>Value1</Test> <Test>Value2</Test> </Root> ''' result.xml.check( element=xml_2, xpath='/Root/Test', tags=['Value1', 'Value2'], description='XML check for tags in the given xpath.' ) xml_3 = ''' <SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"> <SOAP-ENV:Header/> <SOAP-ENV:Body> <ns0:message xmlns:ns0="http://testplan">Hello world!</ns0:message> </SOAP-ENV:Body> </SOAP-ENV:Envelope> ''' result.xml.check( element=xml_3, xpath='//*/a:message', tags=[re.compile(r'Hello*')], namespaces={"a": "http://testplan"}, description='XML check with namespace matching.' )Sample output:
$ test_plan.py --verbose ... Simple XML check for existence of xpath. - Pass xpath: /Root/Test xpath: `/Root/Test` exists in the XML. XML check for tags in the given xpath. - Pass xpath: /Root/Test Tags: Value1 == Value1 Value2 == Value2 XML check with namespace matching. - Pass xpath: //*/a:message Namespaces: {'a': 'http://testplan'} Tags: Hello world! == REGEX('Hello*') ...
Logfile Assertions (result.logfile)
Contains assertion methods that operates on log files equipped with
LogMatcher or RemoteLogMatcher.
result.logfile.seek_eof
Set the position of LogMatcher to end of logfile, with operation logged to the report.
from testplan.common.utils.match import LogMatcher log_matcher = LogMatcher("my_log_file") @testcase def sample_testcase(self, env, result): result.logfile.seek_eof(log_matcher, description="SEEKING")
Sample output:
$ ./test_plan.py --verbose ... SEEKING LogMatcher[...] now at <inode XXX, position XXX> ...
result.logfile.match
Match patterns in logfile using LogMatcher, with matching results logged to the report.
from testplan.common.utils.match import LogMatcher log_matcher = LogMatcher("my_log_file") @testcase def sample_testcase(self, env, result): result.logfile.match( log_matcher, r".*passed.*", timeout=2.0, description="my logfile match assertion", )
Sample output:
$ ./test_plan.py --verbose ... my logfile match assertion - Pass Pattern: `.*passed.*` ...
Match patterns in remote logfiles using RemoteLogMatcher, with matching results logged to the report.
from testplan.common.utils.match import RemoteLogMatcher # Initialize a matcher for logs on a remote host remote_log_matcher = RemoteLogMatcher( host="remote-server.example.com", log_path="/path/to/application.log" ) @testcase def sample_remote_log_testcase(self, env, result): result.logfile.match( remote_log_matcher, r".*Application started successfully.*", timeout=5.0, description="verify application startup on remote host", )
Sample output:
$ ./test_plan.py --verbose ... verify application startup on remote host - Pass Pattern: `.*Application started successfully.*` File: `/path/to/application.log` ...
result.logfile.expect
Call as context manager for pattern matching in logfile, given expected lines
(indirectly) produced by context manager body, with matching results logged to the
report. On enter doing position seeking operation as
result.logfile.seek_eof,
on exit doing matching operation as
result.logfile.match.
from testplan.common.utils.match import LogMatcher log_matcher = LogMatcher("my_log_file") @testcase def sample_testcase(self, env, result): with result.logfile.expect( log_matcher, r".*passed.*", timeout=2.0, description="my logfile match assertion", ): with open("my_log_file", "r+") as f: f.write("passed passed passed\n") f.write("failed failed failed\n")
Sample output:
$ ./test_plan.py --verbose ... my logfile match assertion - Pass Pattern: `.*passed.*` ...
Graph Visualisation
This graphing tool will allow you to produce interactive data visualisations inside the web UI
This method takes 5 arguments:
result.graph(graph_type, graph_data, description, series_options, graph_options)result.graph('Line', { 'graph 1':[ {'x': 0, 'y': 8}, {'x': 1, 'y': 5} ], 'graph 2':[ {'x': 1, 'y': 3}, {'x': 2, 'y': 5} ] }, description='Line Graph', series_options={ 'graph 1':{'colour': 'red'}, 'graph 2':{'colour': 'blue'}, }, graph_options={'xAxisTitle': 'Time', 'yAxisTitle': 'Volume'} )
graph_type - string
Specifies the type of graph displayed, there are currently six choices:
Line,
Scatter,
Bar,
Pie,
Hexbin,
Contour,
Whisker
graph_data - dict
This contains the data for each series and is required in a specific format:
{ ‘series 1’: data_for_series_1, ‘series 2’: data_for_series_2}
This would be used for a graph with two data sets to be displayed on the same axis.
For one data set, this format is still required:
{ ‘series 1’: data_for_series_1 }
The data format required for each type is shown below:
Line, Scatter, Hexbin and Contour: Array[ Dict{ ‘x’: int, ‘y’:int } ]
[ {'x': 0, 'y': 8}, {'x': 1, 'y': 5}, {'x': 2, 'y': 4} ]Bar: Array[ Dict{ ‘x’: string, ‘y’:int } ]
[ {'x': 'A', 'y': 10}, {'x': 'B', 'y': 5}, {'x': 'C', 'y': 15} ]Pie: Array[ Dict{ ‘angle’: int, ‘color’: string, ‘name’: string } ]
[ {'angle': 1, 'color': '#89DAC1', 'name': 'car'}, {'angle': 2, 'color': 'red', 'name': 'bus'}, {'angle': 5, 'color': '#1E96BE', 'name': 'cycle'} ]**N.B.** - angle represents proportion of bar graph e.g car will be 1/8th of the pie chart
Whisker: Array[ Dict{ ‘x’: int, ‘y’: int, ‘xVariance’: int, ‘yVariance’: int } ]
[ {'x': 1, 'y': 10, 'xVariance': 0.5, 'yVariance': 2}, {'x': 1.7, 'y': 12, 'xVariance': 1, 'yVariance': 1}, {'x': 2, 'y': 5, 'xVariance': 0, 'yVariance': 0} ]
description - string
The title of your graph
series_options - dict
The individual options for each data set. Again, this supports multiple series so expects the format
{ ‘series 1’: options_for_series_1, ‘series 2’: options_for_series_2 }
Note: the name MUST be identical to that in the graph_data dict.
Again, for one data set this format is still required:
{ ‘series 1’: options_for_series_1 }
series_options={ 'Bar 1': {"colour": "green"}, 'Bar 2': {"colour": "purple"}, }
Currently supported series options:
‘colour’ - str the colour of that data set on the graph
(DEFAULT: Random colour - if you do not like your randomly assigned colour, refresh the page for a new one if you’re feelin’ lucky!)
Valid inputs for colour include:
RGB colours e.g (‘#8080ff’, ‘#c6e486’)
Basic colour names e.g (‘red’, ‘orange’, ‘yellow’)
e.g {‘colour’: ‘red’}
graph_options - dict
The options for the entire graph
graph_options = {'xAxisTitle': 'Time', 'yAxisTitle': 'Volume', 'legend': True}
Currently supported graph options:
‘xAxisTitle’ - str the title on the x Axis
e.g {‘xAxisTitle’: ‘Time’}
‘yAxisTitle’ - str the title on the y Axis
e.g {‘yAxisTitle’: ‘Volume’}
‘legend’ - bool whether to display the data set name legend
(DEFAULT: False)
e.g {‘legend’: True}
Custom Comparators
Some assertion methods can make use of custom comparators, which are located at testplan.common.utils.comparison module.
These utilities are simple, composable and callable objects and produce more readable output compared to plain lambda functions.
>>> from testplan.common.utils import comparison >>> plain_comparator = lambda value: 2 < value < 5 >>> custom_comparator = comparison.Greater(2) & comparison.Less(5) >>> plain_comparator(3) == custom_comparator(3) == True True >>> str(plain_comparator) '<function <lambda> at 0xf6994a74>' >>> str(custom_comparator) (<value> > 2 and <value> < 5)
Styling Assertions on UI
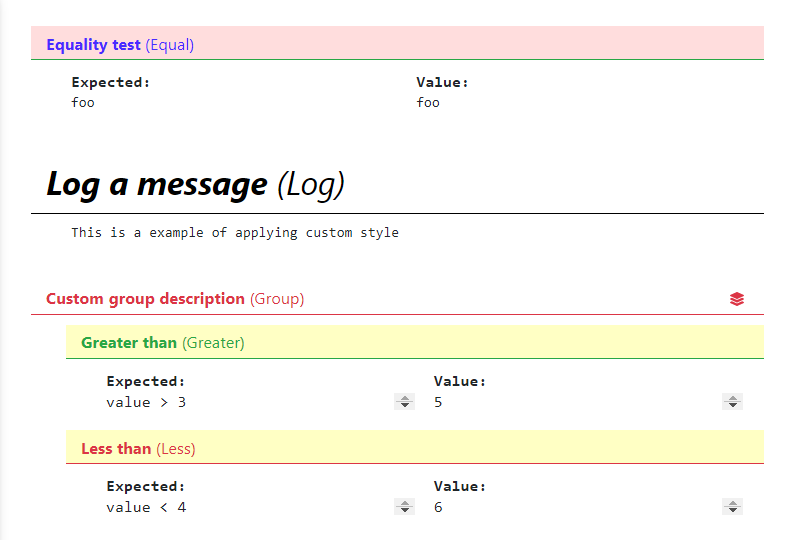
It is possible for user to define HTML styles (color, size, font, background, etc) for each assertion header on web UI, this can be used to make certain assertions stand out.
Most assertion methods (except raises, not_raises, group) can accept an argument
custom_style which complies with standard CSS 3 syntax, and the style will be applied to
that assertion header. A typical usage is to change the background color of assertion headers
or enlarge the font size so that concerned information can be easily found at a glance.
@testcase def sample_testcase(self, env, result): result.equal( 'foo', 'foo', description='Equality example', custom_style={'background-color': '#FFDDDD'}, )
Refer to the example here , as a result the web UI will look like this: